本文共 4029 字,大约阅读时间需要 13 分钟。

导读:Flink Forward是由Apache官方授权,Apache Flink 商业公司dataArtisans(Flink核心作者创办)发起,阿里巴巴、 Uber、Airbnb、Netflix等公司参与的国际型会议。日前Flink Forward柏林会议刚刚闭幕,今天,我们一起分享会议内容。
九月的柏林,比杭州多了一丝清冽,与之相对应的,是如火如荼的2018 Flink Forward Berlin(以下简称FFB)会场。在这个初秋,Apache Flink 核心贡献者、行业先锋、实践专家在这里齐聚一堂,围绕Flink发展现状,生态与未来,共话计算之浪潮。值得一提的是,阿里巴巴作为ApacheFlink主要贡献方,受邀参与此次盛会,并发表演讲。
本文主要来自阿里巴巴研究员量仔和阿里巴巴资深技术专家莫问在2018 Flink Forward Berlin会后的分享。
众所周知,Apache Flink是一款分布式、高性能、高可用、高精确的为数据流应用而生的开源流式处理框架。Flink的核心是在数据流上提供数据分发、通信、具备容错的分布式计算。同时,Flink在流处理引擎上提供了批流融合计算能力,以及SQL表达能力。
Flink Forward旨在汇集大数据领域一流人才共同探讨流计算、实时分析等领先技术。通过参会不仅可以了解到Flink社区的最新动态和发展计划,还可以了解到国内外一线大厂围绕Flink生态的生产实践经验,是Flink开发者和使用者不可错过的盛会。
Leager 横空出世, ACID有新解
此次柏林Flink Forward上对于Flink的未来,展现出了几个新的方向:第一,Flink在解决传统的分布式事务(ACID)上做了更多改进。此次柏林Flink Forward上针对ACID提出了一种新的解法,这种方式比传统的分布式事务在性能上有更强的优势,走出了Streaming原有的领域和相关方面的扩张。Flink创建初期主要解决的是流计算方向的问题,随着生态的发展,同时也为解决多方面的需求,Flink 不断提升其解决更多场景的能力。正因如此,当下Flink正在做的场景就是从流计算向一个通用的场景转变。
第二,阿里巴巴在FFB上宣布对于批和流两种计算模型做了更深度的融合,批计算能力对比当前Flink社区版本有了数量级的提升;与此同时,在大数据生态方面,Flink从流处理到现在的批流融合,得到了质的飞跃。从长远角度看,无论是机器学习还是到其他各个方面的场景,会逐渐将整个Flink生态完善起来。
同时,在大会第一天上午的主论坛中,dataArtisans重磅发布了基于云计算的分布式事务(ACID)的产品Leager,目前Leager发布了2个版本,一个是可试用的单机Streaming版本,另外一个是River版本,在DA Platform上有售卖。
Leager API在github上可以查看:
https://github.com/dataArtisans/da-streamingledger
大会现场,通过一个简单的Demo,dataArtisans CTO Stephan Ewen 向听众介绍了在金融行业如何通过Leager解决银行的转账问题。这是 Flink 生态上,一个新的分布式事务的解决方案。
批流统一,大势所趋
Flink在创建之初,就凭借其可以优雅支持多种计算模式的架构,被业界认为具备先天优势,这也是几年前阿里巴巴选择Flink引擎的一个重要原因。如今阿里凭借其领先的技术水平,持续优化Flink在批计算处理方面的性能,使批与流之间的界限日渐消弭,真正实现批流统一。
对比Flink,其劲敌Spark也有流批统一的概念,但做法与之大有不同。Spark是基于批处理做流处理,并且Spark在架构上先天不足,导致其在性能上的提升举步维艰,同时,天然批处理为主的架构为Spark进一步提高吞吐量带来巨大障碍。而Flink的批流统一,从另外一个方向去看,是将流作为一切计算的基础。这个方案与Spark相比,最本质的区别在于:第一, Flink是天然的流处理引擎,允许其在流上做到极致;第二,在流上做批,架构上允许把批处理也做到极致。
尽管在当初选择大数据计算引擎时,Spark无论是从热度还是生态角度也许都比Flink更胜一筹。但从长远考虑,阿里看到其在架构上存在几乎难以逾越的鸿沟,虽然Flink现在没有Spark生态那么火热,但是Flink的先天架构优势,加之诸如阿里这些大厂的支持,相信Flink会开辟出一片新的天空,且走的更远。
三年前,在内部启动Flink时,因其开源产品的特性,很难满足阿里大体量的特定场景需求,为了将Flink在阿里巴巴真正运行起来,阿里巴巴实时计算团队做了大量的优化,并命名Flink在阿里巴巴内部的版本为Blink。Blink在迭代优化的过程中,也在不断向社区捐赠代码,真正做到“取之开源,用之开源”。
目前,阿里巴巴的实时业务场景,从搜索到广告、数据平台、安全等等。所有大的场景都是基于阿里巴巴内部版本Blink展开,同时通过Stream Compute产品在阿里提供公共云服务。在Flink Forward上,阿里为Flink提出的批流融合新突破,这也是架构上的一个新方向,并已经得到了初步的成果和验证。
蒋晓伟认为Flink新的发展方向有两个,第一个是在传统数据处理领域:包括批流统一、机器学习、以及如何把AI workload融合进来;第二个是Flink和微服务的技术融合创新,从而为在线服务领域带来新的变革。这使得Flink在生态上,也会拥有大的想象空间。
Flink Forward过去只在德国柏林、美国旧金山举办。今年将由阿里巴巴作为独家承办方将这一盛会引入中国,于今年12月在北京落地,共建生态。更多会议信息将于近期发布,敬请关注。
关于Flink,也许你还想了解这些事情
Q:架构上,Flink和Spark相比最大的特点是什么,为什么Flink更适合做批流融合统一引擎?
Flink底层是基于Streaming,而Spark底层是基于Batch;这是两个截然不同的做法,Spark是在RDD的Batch上构建一切,因此Spark构建Streaming需要把RDD做的非常小。 在粗粒度上面构建一个细粒度,在计算上会有很多瓶颈,架构上的问题很难去解决,这也是Spark在Streaming上做的一些事。而Flink天然就是Streaming, Batch就是在Bounded Streaming上的延伸,在架构上是没有多少损失的。因此Flink在走Batch这条路上走下去是没有太多障碍的,并且阿里在Flink上面做了很多针对Batch场景的优化和改进,例如:JOB的调度以及容错,数据Shuffe,任务执行优化上都做了很多工作。
Q: 机器学习在Flink平台应用案例多吗?Flink在AI时代怎么同Spark竞争?
Flink平台应用案例还是较多的,在阿里内部,几乎一半的计算都是在机器学习上,近年来相当重要的一个趋势就是朝着实时机器学习发展。Flink的批流融合架构,使得其无论在离线还是实时机器学习领域都可以发挥。首先,在深度学习方面,现在很多算法在业务场景中都得到了很好的应用,作为一个好的计算引擎,都需要和深度学习很好的集成,Flink在这方面也正在做大量的工作;其次,对于传统的机器学习,阿里在Flink上也做了很多工作,并实现以及改进了很多机器学习算法。
Q:未来Flink和Blink发展差异性,或是有多少Feature没办法反馈给社区,对社区是不是一种损失?
阿里特殊的业务体量是很多公司暂时达不到的,这使得阿里在发展的过程中会更早遇到一些技术瓶颈,自然也会更早的解决这些问题。在解决问题的过程中,阿里会将对Flink的改进方案经过一定时间的验证确保稳定可行后再贡献给Flink开源社区。当然,Flink社区也是由很多其他公司在支持和使用,所以向社区贡献的过程和节奏是需要一定耐心和时间的,但这个过程肯定会越来越快,越来越顺畅。
Q:持续不定期的批处理算批还是算流?
批和流的分类不是非黑即白的问题,二者的界限会在批流统一趋势下逐渐模糊。我们真正要关心的问题是,选择执行计划是什么样的方式。比如一方面从Kafka流式获取数据,同时定期还要从HBase批量获取数据,这个时候已经分不清楚是批还是流任务了,这就是真正的批流融合了。
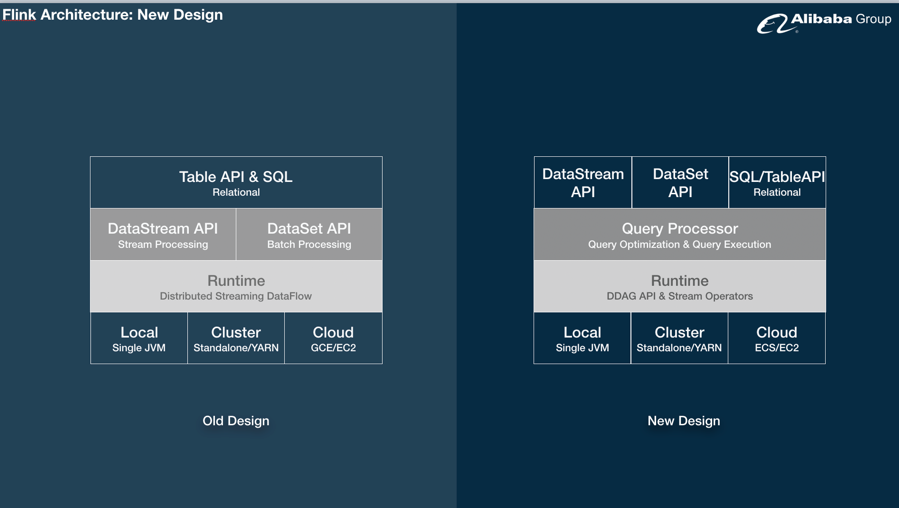
Q: Flink DataSet和DataStream API是否能统一?
目前TableAPI/SQL是统一的,但DataSet和DataStream是针对流和批不同的2个API,阿里现在提出了一个更加底层的DAGAPI,即一个有限无环图来表达计算拓扑的概念,这个拓扑可以表达各种流或者批的语义,图上的点表示算子(可以是流也可以是批算子),中间数据是流式传输还是批处理传输,整个图也可以是流批混合的,例如:一个Source从Kafka读一个DataStream,另一个Source定期从HDFS或者HBase读一个DataSet。其他API都可以基于DAGAPI来定义语义,以后DataSet API也许可以和DataStream整合掉,在DataStream中增加有限流的算子,就可以实现批处理了。
Q: Flink SQL 跟 GreenPlum 这样MPP架构的OLAP计算引擎 比起来优势在哪?
从处理场景来说,Flink SQL更广一些,例如:Flink SQL不仅支持短Query,还可以有长query。Flink在Failover上面做的比较全面,但OLAP都是短Query,不怎么需要Failover,因此OLAP引擎可以认为是一种特殊的批处理场景,有着自己特殊的需求和特性。
转载地址:http://sakix.baihongyu.com/